概要
SEが何ヶ月も調査しているはずなのに一向に解決しない性能問題。ギブアップ寸前の問題の相談を受け、解決に導いていくプロセスを現場の視点で紹介します。性能改善の現場ではメインフレームの本質が見えてきます。
2.1 性能評価・改善のプロセス
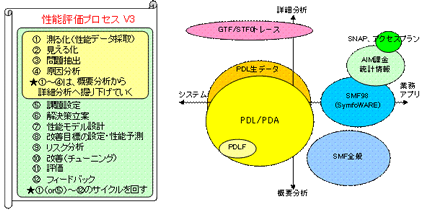
GSを担当しているメーカのSEでさえ性能評価・改善の手順や手法を知らないのが実状です。そこで、最初に図3に示す性能評価プロセス(左)と使用する性能データ(右)を一通り説明し、作業の進め方を検討しました。ポイントは以下の3点と考えています。 ①~④では現状分析を網羅的に行い、必要に応じて詳細分析を行うこと 根本原因を究明し、適切な課題設定⑤を行うこと 効果的な改善を行い、⑤~⑫のサイクルを効率よく回すこと (※改善作業はお客様またはSEが行います。)
2.2 性能評価・改善プロジェクトの進め方(第1、2フェーズ)
性能評価・改善プロジェクトは4つのフェーズで実施しました。

2.3 自信を持たせる
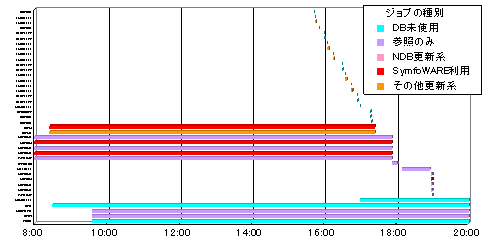
実際に使っているオンライン業務のオペレーションを見せてもらったところ、4秒くらい返ってこない処理がありました。A(有賀)とU(お客様)の会話です。
A 「今の画面、何の処理ですか?」
U 「問題になっているxx業務の照会処理です」
A 「もう一度できますか?」
U 「はい・・・、やはり4秒くらいかかりますね」
A 「どうして今そんなに遅いのでしょう? バッチ処理との排他待ちですか?」
U 「いや、バッチ処理は今実行されていないと思います」
A 「本番環境でトレースを採取して動きを分析したいのですができますか?」
U 「確認しますが、問題ないと思います」
連載一覧
筆者紹介

株式会社アイビスインターナショナル 代表取締役
1963年生まれ。1985年富士通株式会社入社。1992年~2003年まで社内共通技術部門で国内外のメインフレームの性能コンサルティングを実施、担当したシステム数は1,000を超える。2000年からは大規模SIプロジェクトへの品質コンサルティング部門も立ち上げた。
2004年に株式会社アイビスインターナショナルを設立。富士通メインフレームの性能コンサルティングとIT統制コンサルティングを行っている。
技術情報はhttp://www.ibisinc.co.jp/で公開中。富士通やSI’erからのアクセスが多い。
当サイトには、同名シリーズ「富士通メインフレームの本質を見る~IT全般統制の考え方」を3回、「富士通メインフレームの本質を見る~バッチ処理の性能評価と改善事例から」を6回、「富士通メインフレームの本質を見る~CPUリプレースの考え方」を3回、「富士通メインフレームの本質を見る~性能改善の現場」を7回、「富士通メインフレームの本質を見る~2009年度の最新トッピックス」を3回、「富士通メインフレームの本質を見る~2008年度の最新トピックス」を2回にわたり掲載。
コメント
投稿にはログインしてください