株式会社アルテシード
代表取締役 神居 俊哉(かみい としや)
概要
メインフレームはあなたの企業を始め、多くの企業の基幹システムを支えています。とりわけ金融、製造、公共など、日本の基幹産業で今日も働いています。新しいニュースは少ないものの、まさに業務を確実に処理するための大きな存在です。世の中にはあまり知られていませんが、オープン系をいまだに超えている技術、ノウハウが生きている分野です。黙って国を支えているITといっても過言ではないと思います。
そんなシステムを品質よく、安定して運用するためには、業務運用マニュアルや先輩・上司からの言い伝えだけでなく、確かな知識が必要です。
ここではメインフレームの代表的OSであるMVS(z/OS)の基本的なしくみについて、運用部門に携わる新人エンジニアに必要なものを解説します。
プログラムで処理するデータの集合が「ファイル」です。OSにはファイルシステムというコンピュータに接続された外部記憶装置上のデータを整理して管理・整理・操作する機能があります。OSごとに様々なファイルシステムが存在し、WindowsではFATとNTFSという階層型のファイルシステムが使われます。MVSにもファイルシステムはあり、DFPあるいはデータ管理と呼ばれます。z/OSではHFSと呼ばれる階層型ファイルシステムがサポートされていますが、ここではMVSシステムが基本としてサポートしてきたファイルシステムの概要について解説します。
データセットとファイル
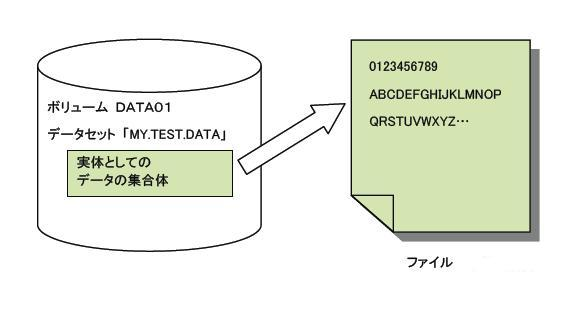
MVSではファイルを「データセット」と呼びます。ファイルとデータセットは、しばしば同じ意味で使われますが、本来は使い分けられるもので、それを理解することは重要です。「データセット」とは、ディスクや磁気テープ上に記録されているデータの集合としての実体を指します。一方ファイルは実体ではなく論理的なデータの集合体として捉えたもので、プログラムで扱うデータの集合を指すものと考えることができます。

データセットとファイルの違いは、JCLにおけるDD文の連結機能を見るとわかりやすくなります。上記を例に取ると、DD名SYSUT1がファイル、個々のDD文がデータセットです。プログラムはファイル名(アクセス名)である、SYSUT1でデータにアクセスします。ファイルSYSUT1は、3つのデータセットDATA1,DATA2,DATA3によって構成されるわけです。
データセット名
データセットに付ける名前がデータセット名です。データセット名は1つまたは複数の修飾子(Qualify)で構成されます。修飾子はセグメントとも呼ばれます。各々の修飾子は1から8文字で、そのうち先頭は英字(AからZ)または国別文字(#@$または\)でなければなりません。残りの7文字は、英字、数字(0から9)、国別文字、またはハイフン(-)のいずれかです。修飾子はピリオド(.)によって連結し、データセット名を構成します。データセット名はすべての修飾子およびピリオドを含めて44文字までを使用することができます。ただし磁気テープ上のデータセットには17文字までの名前しか付けられません。17文字以上の名前を付けた場合は後方の17文字で認識されます。

MVSではファイルシステム自体は階層型ではありませんが、データセット名は階層的に命名することができるようになっています。後に紹介するカタログの機能と組み合わせて、名前によって階層管理ができるようになっています。
デバイスとボリューム
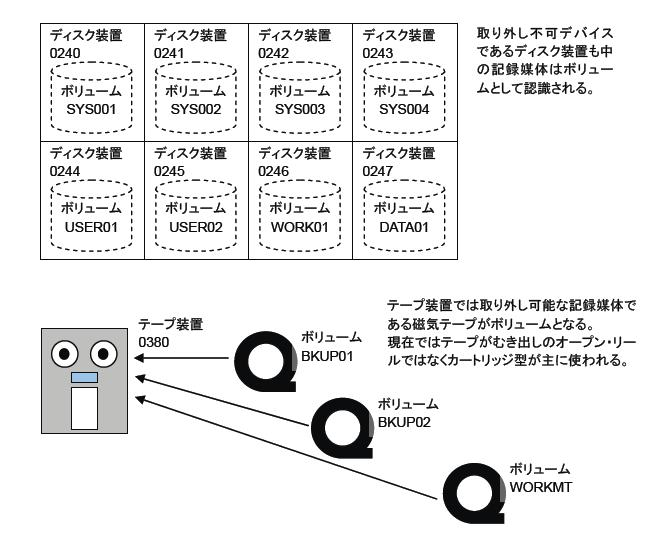
データセットはディスクやテープに記録され保存されます。ハードウェアとしてのディスク装置やテープ装置がデバイスです。これらのデバイスには記録媒体が取り付けられ、実際のデータが記録されます。MVSではこの記録媒体をボリュームと呼びます。ボリュームとはデータセットを格納する入れ物(器)と言っていいでしょう。デバイスとボリュームは必ずしも1対1になりません。特にテープ装置で考えるとわかりやすいです(PCなどのCD-ROMも同じです。機械の方がデバイスで、記録するメディアとしてのCD-ROMがボリュームに相当します)。
デバイス
MVSではデバイス(装置)には番号が付けられユニットとして管理されます。すべての入出力デバイスが対象になり、番号は4桁の16進数で構成されています。これを装置番号(Unit Number)と呼びます。VOS3では装置番号の代わりにニーモニック名と呼ばれる3文字の識別名が使えます。テープ装置ならT00,T01、DASDならK01,K02などのようにです。
ボリューム
テープ装置では取り外し可能な記録媒体が使われます。リールとかカートリッジと呼ばれるものです。同じ装置に複数のテープが取り付けられる(交互にではあるが)ため、テープ上のデータセットは装置番号では正しく指し示すことができません。そこで装置に取り付けられるテープには名前を付けて識別できるようにしています。これがボリューム通し番号(ボリューム名)で、最大6文字までの英数字を使用することができます。ボリュームの考え方はディスク装置でも同じです。ディスクの場合は取り外し可能媒体ではありませんが考え方として装置と記録媒体を分けていると言うことです。
ディスク・テープ共にボリュームには先頭にボリューム・ラベルがあり、ボリューム通し番号と所有者名などが書き込まれています。ボリューム通し番号は個々のボリュームに付けられる識別名です。初期の頃はテープも容量が小さく、1つのデータセットが何本ものボリュームにまたがって記録されることも多かったので、通し番号の言い方の方がより実態を表していたのですが、ディスクに関してはボリューム名の方が表現としてわかりやすいです。そのため正確にはボリューム通し番号(Volume Serial Number)ですが、現在ではボリューム名と呼ばれることが多いです。またVOLSERとも表記されます。DASDの場合はさらにVTOC(Volume Table Of Contents:ボリューム目録)が置かれます。VTOCにはDASD内の各データセットがどのサイズでどの位置に置かれているか、どのような形式のレコードか、DASD内の空き容量や空き位置などの情報が格納されており、ボリュームのインデックスとして使われます。またデータセットは必ずしも連続した場所に置かれるとは限りません。DASD内の空き状態に応じて複数に分割されて配置される場合もあります。この場合のデータセットを構成する1つ1つの要素(連続した物理レコードの集合)をエクステントと呼びます。 磁気テープ・ボリュームは標準ラベル(SL)とラベルなし(NL)の2つの形式に分かれます。SLでは先頭にボリューム・ラベルを持ち、データセットの前後に見出し・終了のラベルが書かれ、テープ内で順番にデータセットが並んでいます。ラベルにはデータセットの名前、レコード形式、ブロック長およびレコード長なども記録されています。一方のNLテープでは一切のラベルがなく、単にデータセット内容が順番にならんでいるだけです。そのため取り扱いがやや面倒で、テープ内のデータセットのレコード形式やブロック長、レコード長があらかじめわかっていないとデータを読み込むことができません。またどのデータセットがテープ内で何番目に書き込まれているかもわかっていなければなりません。
マウント
記録媒体を装置に取り付けることをMVSではマウントと呼びます。デバイスはIPL時に認識されますが、ボリュームはマウントによってMVSに認識されます。ディスクのように装置と媒体が一体になっていてもマウントの手続きは必要で、いつマウントするかのタイミングの違いがあるだけです。通常ディスクはIPL時に自動的に行われ、テープはジョブによってボリュームが要求されたときに行われます。あらかじめ装置に媒体が取り付けられていなければ、MVSはオペレーターにボリュームの取り付けをメッセージによって通知します。
カタログ
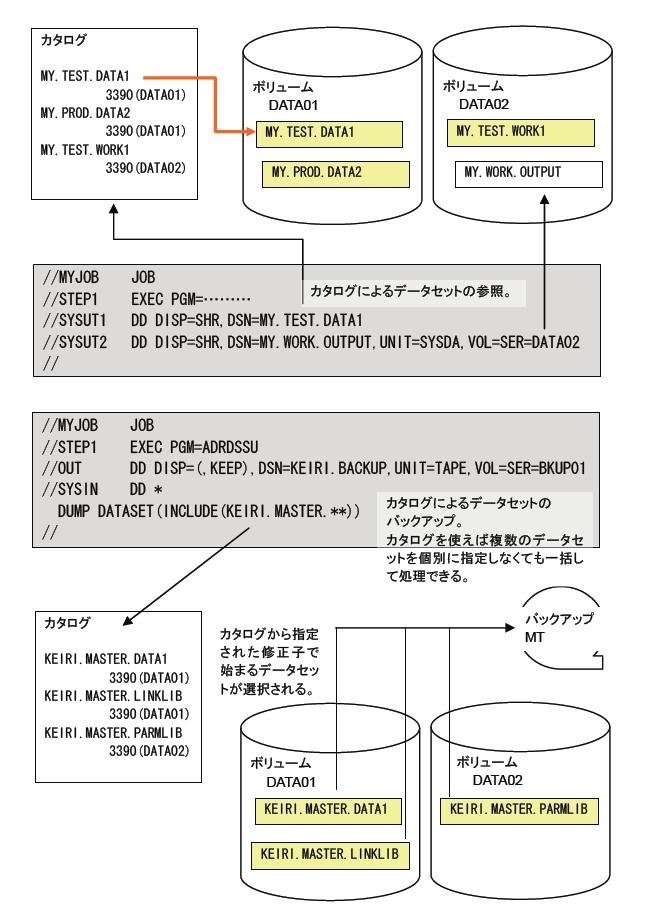
カタログはデータセット名およびそれが作成された装置の種類とボリューム名(テープであればテープ内の順序番号も含む)を記録しておく機能です。カタログされたデータセットは、DD文にデータセット名とアクセス後の後始末方法だけを指定すればアクセスできます。ユーザーは個々のデータセットが格納されているボリューム名を覚えたり、管理したりする必要がなくなります。MVSはDD文にボリュームの指定がないとカタログを探索してデータセットの場所を求めます。 またカタログにはデータセットを名前で管理するという面も併せ持ちます。これによってデータセットをバックアップする際などに、ボリュームを意識することなく、特定の用途にグループ化されたデータセットを一度にまとめて処理することができます。例えば経理業務のマスターファイルがKEIRI.MASTER.xxxxxxxxのように命名されていれば、KEIRI.MASTERで始まるすべてのデータセットを1度の操作で容易にバックアップを行うことができます。この時バックアップの対象になるデータセットがどのボリュームに格納されているかを意識する必要はありません。またカタログを使用する場合は異なるボリュームであっても同じ名前のデータセットを作成することはできなくなります。そのため同名のデータセットが散在し、どれが最新のものか、どれが正しい内容のものかが不明になるなどと言ったことも起きません。なおカタログを上手に使うためには使用するデータセット名を正しく階層化することが必要になります。
アロケーション
ジョブ・ステップで使用するデータセットは、あらかじめJCLのDD文によって定義されます。MVSはジョブ・ステップの開始時に、定義されたデータセットを探し出し、利用できるように準備します。これがアロケーションで、データセットを資源としてジョブ・ステップに割り当てます。プログラムから見た場合は、論理的なデータの集合であるファイルを、データの実体であるデータセットに関連付けることになります。
プログラムで処理するデータの集合が「ファイル」、DASDやTAPEなど記録媒体上の実体データが「データセット」、単なる呼び方の違いではない点や、ファイルシステムそのものは階層型ではないが、名前とカタログ機能によって階層管理ができる仕組みになっている点を理解しておきましょう。
次回はデータセットとレコードについてお話しします。
連載一覧
筆者紹介
http://www.arteceed.com
ビーコンITにて約20年にわたり、独SoftwareAG社のTPモニター・ソフトウェア製品などのサポートや同製品の富士通、日立OSへのポーティングのためのシステムプログラム開発などを行ってきた。現在はメインフレーム・コンピュータに関する技術スキルを後進に伝え、基礎知識や実践的な技術を広めることで企業の情報システムを支えるべく、株式会社アルテシードを設立。併せて、メインフレーム・コンピュータ技術情報サイト“「メインフレーム・コンピュータ」で遊ぼう”(http://www.arteceed.net/)
を主宰し、z/OSやMSP、VOS3など代表的なメインフレーム・システムのコミュニティ活動を展開開始。基本スキルから高度なプログラミング技術の解説、サンプルの提供、ならびに関連する各種の技術情報の交換なども行っている。
メインフレームでは約20年ぶりの和書、「メインフレーム実践ハンドブック」を3月にリックテレコム社より刊行。
コメント
投稿にはログインしてください