概要
多くのSEはシステムの性能評価が不得手です。そのため、お客様がシステム性能の主導権を握れると、コスト削減・品質向上につながります。バッチ処理の性能改善事例を使い、性能問題の裏にある本質を皆さんと一緒に考えていきます。事例は富士通メインフレーム上のものですが、改善へのプロセスや本質はどのメーカでも共通点があると思います。
「富士通メインフレームの本質を見る~バッチ処理の性能評価と改善事例から」は今回が最終回となりますので、性能評価の裏側を少し紹介したいと思います。
昔の同僚と話すことがありますが、私のささやかな自慢は、今でもユーザ先で端末を叩けること、性能データはもちろんトレースもプログラムも自分で読めること、そして作業を始めたらトイレ休憩なしに8時間は没頭できることです。マシン室に軟禁されているともいえますが…
性能問題が起きている現場できれいごとは通りません。事実を迅速かつ客観的に把握するとともに、組織や人間関係も観察します。関係者に自分を信頼してもらう努力をし、自分の発言には100%責任を持たなければなりません。
メーカ内で性能評価が不人気な原因はこの辺りにあるのかもしれません。
手法3~バッチ処理の処理時間モデルⅡ
性能問題はシステム移行や業務追加後に起きる傾向があります。
原因は、何かミスをしたのか、潜在していた問題が表面化したのかの2つに集約されます。このときのバッチ処理の処理時間モデルⅡを図9に示します。
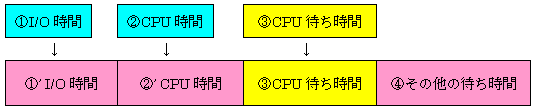
■解説
- ①’ I/O時間(I/O待ち時間は含まない)が延びることがある。
I/O時間=I/O回数×I/O性能値
I/O性能が悪化する要因は、DISK側の問題(キャッシュヒット率の低下、ファームの問題など)や本体側の問題(チャネル負荷の増加~特にXSP)が考えられる。
性能データからI/O時間の増加を把握することは意外とむずかしい。 - ②’ CPU時間が延びることがある。
CPU時間=ダイナミックステップ数×CPU性能値
同等性能のCPUに単純移行しても、CPU性能は±20%程度変動するものである。
AVM(仮想システム)化するときは、オーバヘッドを考慮する必要がある。 - ④その他の待ち時間の例【OSの内部処理による待ち】
– カタログアクセスのオーバヘッド、処理待ち(特にXSP)・・・ 補足、表6
– 資源管理(特にXSP)による処理待ち
– スワップイン待ち(特にMSP)・・・ 補足
– RACF(アクセス管理)のオーバヘッド - ④その他の待ち時間の例【AIMの内部処理による待ち】
– データベースの排他制御のオーバヘッド、排他待ち
– ログ管理によるオーバヘッド、処理待ち ・・・ 補足
■④の補足
OSやAIMも、仕様やパラメタの設定で不自然な動きをすることがあります。
このような状況を見つけたときは、事実を素早く確認し、お客様に状況を正しく報告するとともに具体的な改善案を提示するようにしています。実例を3つ紹介します。
カタログ管理簿の構造上の問題【XSP】
ファイルのアロケーション時、ボリューム通番が不明のときはカタログを参照します。
一つのファイルに対し、カタログサーチ時のI/O回数を実測したところ、カタログの圧縮前にはなんと583回もI/Oが出ていたことが判明しました(表6)。圧縮直後は21回まで減少していますが日ごとに増加しています。定期的に圧縮をしないとバッチ処理の性能が劣化するケースです。
AIF端末からジョブをSUBMITしたとき、画面下に *** が出るのに数秒かかるシステムは要注意です。
表6 カタログサーチ時のI/O回数
![]()
スワップイン制御【MSP】
OSはシステムパラメタ(KAAIPSxx)の設定値に従い、目標多重度(該当ドメインでスワップインできる数)を調整します。システムの初期値を使うと、リソースに余裕があるにもかかわらずスワップインが抑えられることがあります。例えば、バッチジョブを20多重で実行しているとき、10個がスワップアウトしてしまうような現象です。
これを改善するには、最低保証多重度を1⇒20に変更する必要があります。
DMN=1,(CNSTR=(1,255),FWKL=10) /* BATCH JOB
⇒ DMN=1,(CNSTR=(20,255),FWKL=10) /* BATCH JOB
※(1,255)は1~255の間で適当に調整します、と解釈する
ログ管理【AIM】
性能評価では、AIMのログ管理(ISMS)にボトルネックがないか確認をします。
特に、HLFには更新後ログデータと課金統計データが格納されます。今後、内部統制対応で使用頻度が一層高まります。
HLFへの書込みデータが滞留するとシステムはスローダウンします。また、HLFのバックアップが間に合わないと、ジョブが異常終了し、システムダウンにつながります。とても重要なチューニングポイントなのですが、SEの認識は低く、今後障害が起きることを危惧しています。
おわりに~性能データはだれのもの
富士通のメインフレームでは図10に示すような性能データを取得することができます。代表的なものはリソースの使用状況を測定するPDL/PDAですが、「正確に」データを取得できるシステムは全体の2割未満と想像しています。 (PDL/PDAの詳細はhttp://www.ibisinc.co.jp/tech_capadata000.htmを参照)
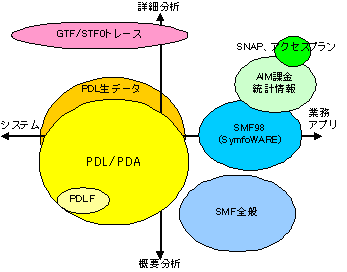
現在では、CPU移行の前後ですら性能データを取得しないのが常識になってしまっています。私にとっては、リソースの使用状況を把握せずに次期CPUを選択できることが信じられませんが双方にメリットがあるのでしょう。
以前、お客様にSEが作ったPDL/PDAの評価報告書を見せて頂き、その内容に大きな衝撃を受けたことがきっかけで、弊社のホームページ上でPDL/PDAの読み方を公開するようになりました。
お客様がメインフレームのシステム性能に関心を高め、自ら主導権を握って頂けると、コスト削減・品質向上に必ずつながると確信しています。
本レポートに関するご意見やご質問等はコメント欄または http://www.ibisinc.co.jp/inq/inq002.htmからお願いします。
連載一覧
筆者紹介

株式会社アイビスインターナショナル 代表取締役
1963年生まれ。1985年富士通株式会社入社。1992年~2003年まで社内共通技術部門で国内外のメインフレームの性能コンサルティングを実施、担当したシステム数は1,000を超える。2000年からは大規模SIプロジェクトへの品質コンサルティング部門も立ち上げた。
2004年に株式会社アイビスインターナショナルを設立。富士通メインフレームの性能コンサルティングとIT統制コンサルティングを行っている。
技術情報はhttp://www.ibisinc.co.jp/で公開中。富士通やSI’erからのアクセスが多い。
当サイトには、同名シリーズ「富士通メインフレームの本質を見る~IT全般統制の考え方」を3回、「富士通メインフレームの本質を見る~バッチ処理の性能評価と改善事例から」を6回、「富士通メインフレームの本質を見る~CPUリプレースの考え方」を3回、「富士通メインフレームの本質を見る~性能改善の現場」を7回、「富士通メインフレームの本質を見る~2009年度の最新トッピックス」を3回、「富士通メインフレームの本質を見る~2008年度の最新トピックス」を2回にわたり掲載。
コメント
投稿にはログインしてください